 A minimalism robotics blog
A minimalism robotics blog[ Multithreading C++ ]
I. Integer Operations and Threads
C++ supports multithreading and concurrency, which can lead to data inconsistency and race conditions when performing integer operations in a multi-threaded environment. Atomic operations are necessary to avoid these problems. In C++, the std::atomic template class provides atomic operations for integer values.
Example integer operation with show the data race
Example integer_operation.cpp the 10 threads with 100,000 increments that should give a final result of 1 million but the result will diferrent bellow:
integer_operation.cpp
// A shared variable is modified by multiple threads
// Integer operations take a single instruction
// Is there a data race?
#include <thread>
#include <iostream>
#include <vector>
int counter = 0;
void task()
{
for (int i = 0; i < 100'000; ++i) {
++counter;
}
}
int main()
{
std::vector<std::thread> tasks;
for (int i = 0; i < 10; ++i)
tasks.push_back(std::thread(task));
for (auto& thr: tasks)
thr.join();
std::cout << counter << '\n';
}
Output
258413 // data races -> the 10 threads with 100,000 increments that should give a final result of 1 million but the result will diferrent
The operation ++count involves 3 operations:
- Pre-fectch the value count
- Increment the value in the processor’s core register
- Publish the new value count
A thread could publish its result after a thread which run later.
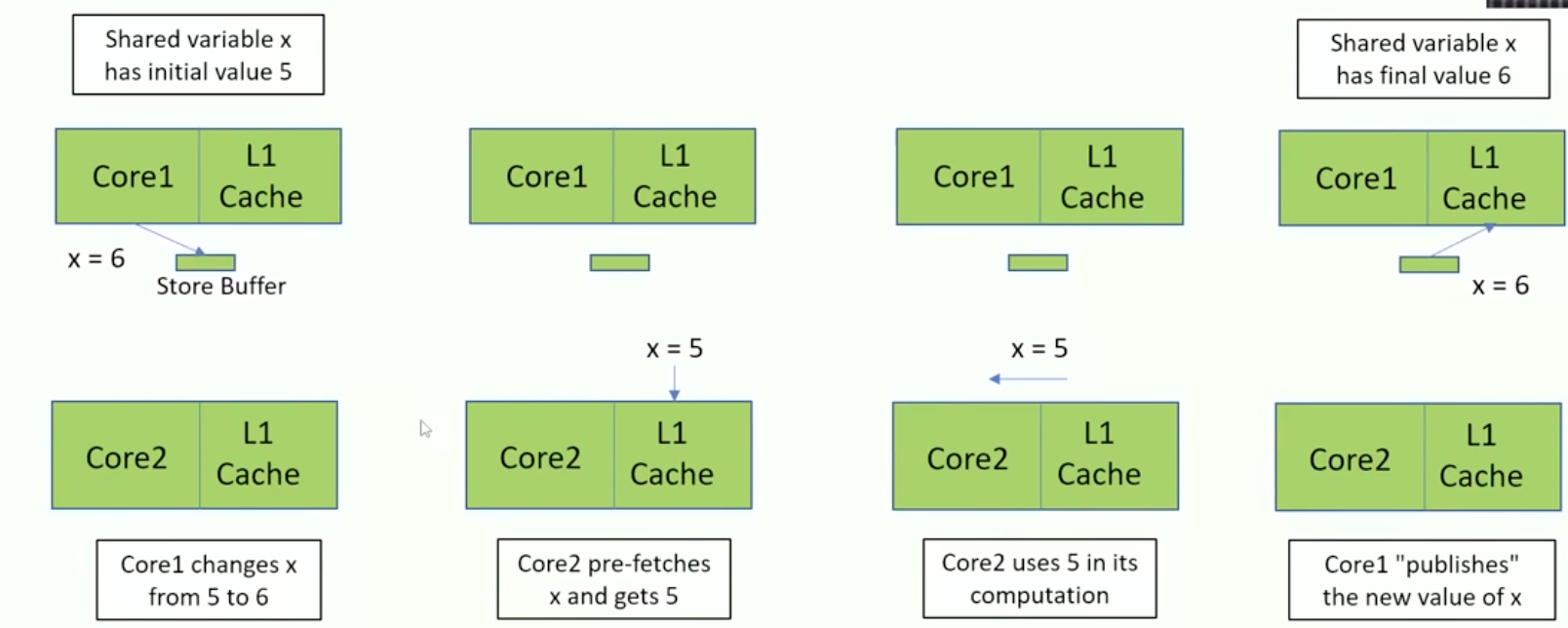
In a multi-threaded environment, integer operations can lead to race conditions and data inconsistency. The following sentences describe an example of this problem:
- Meanwhile, this second thread is unsuspectingly doing its own increment.
- It prefetches the value of x, which is 5. Because this has not been published.
- Then it uses 5 in its calculation, and gets 6.
- And then, later on, this will publish the value 6.
- So we have two threads which publish the value 6.
- In terms of events, the two threads both prefetch the value 5.
- Then they both increment it to 6, and then they both publish the value 6. -The result is that we had the initial value 5 which is incremented twice. The result should be 7, but in fact, it’s only 6.
Solution
We can use the mutex
mutex.cpp
// A shared variable is modified by multiple threads
// Use a mutex to prevent a data race
#include <thread>
#include <iostream>
#include <vector>
#include <mutex>
std::mutex mut;
int counter = 0;
void task()
{
for (int i = 0; i < 100'000; ++i) {
std::lock_guard<std::mutex> lck_guard(mut);
++counter;
}
}
int main()
{
std::vector<std::thread> tasks;
for (int i = 0; i < 10; ++i)
tasks.push_back(std::thread(task));
for (auto& thr: tasks)
thr.join();
std::cout << counter << '\n';
}
Output
1000000 // without data races -> 1 million
Atomic Definition
In C++, the std::atomic template class provides atomic operations for integer values. Each instantiation and full specialization of the std::atomic template defines an atomic type. Objects of atomic types are the only C++ objects that are free from data races. Atomic types encapsulate a value whose access is guaranteed to not cause data races and can be used to synchronize memory accesses among different threads.
When an atomic variable is used, the compiler generates special instructions that prevent the processor from prefetching the value of the variable. The processor only fetches the value when it actually needs it, and the core is forced to flush its stored buffer immediately. This ensures that the results become available to other threads as soon as possible.
In addition, it is possible for the hardware to optimize code by changing the instruction order, which can give better performance. Normally, this will not cause any problems, but in situations where there are dependencies between different cores, it can give incorrect results. It is also possible for the compiler to perform similar optimizations.
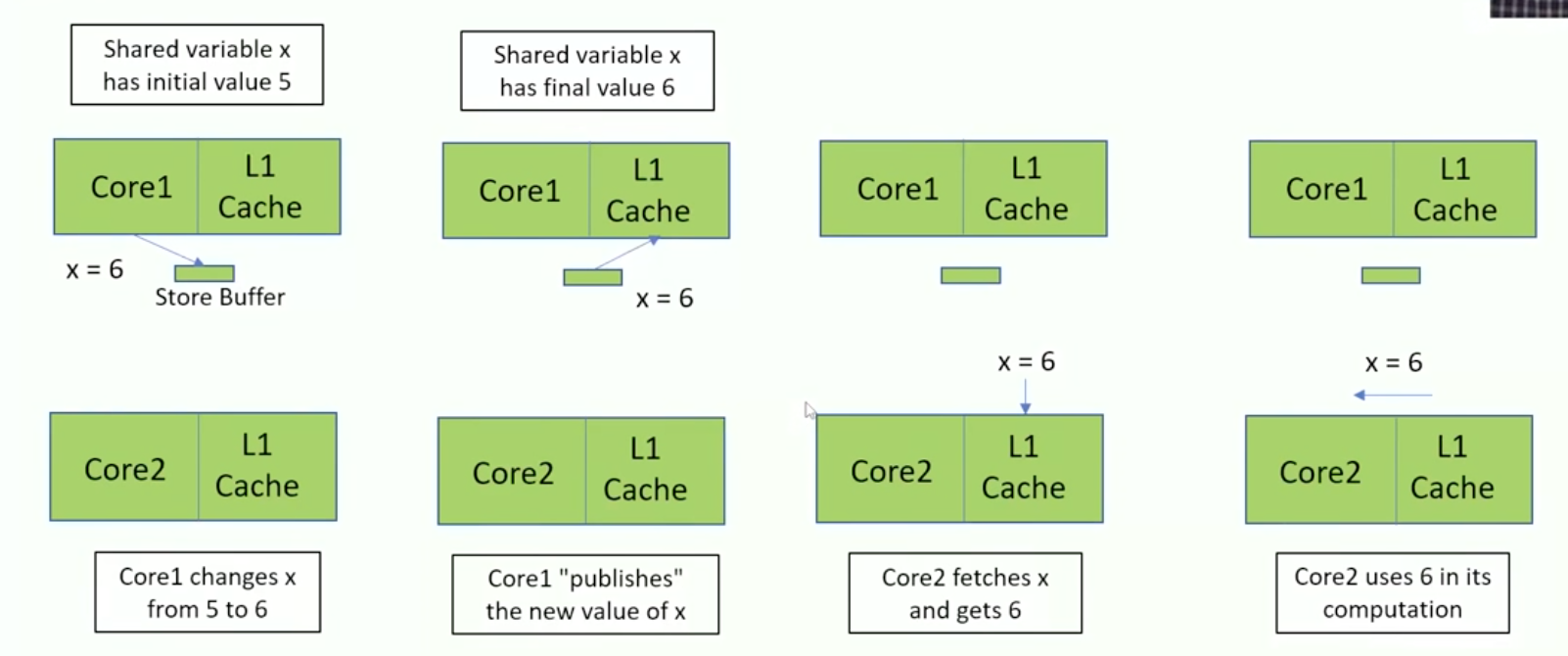
The first core fetches the value 5. It increments it to 6, and then stores the new value. Then the next thread will fetch this new value, increment it and store it. The initial value of 5 is incremented twice, giving the final value 7, which is correct. So we now have the correct scenario without the data race.
Atomic Types
Each instantiation and full specialization of the std::atomic template defines an atomic type. Objects of atomic types are the only C++ objects that are free from data races. Atomic types encapsulate a value whose access is guaranteed to not cause data races and can be used to synchronize memory accesses among different threads.
Example atomic_example.cpp without datarace:
atomic_example.cpp
// A shared variable is modified by multiple threads
// Use an "atomic" variable to prevent a data race
#include <thread>
#include <iostream>
#include <vector>
#include <atomic>
std::atomic<int> counter = 0;
void task()
{
for (int i = 0; i < 100'000; ++i)
++counter;
}
int main()
{
std::vector<std::thread> tasks;
for (int i = 0; i < 10; ++i)
tasks.push_back(std::thread(task));
for (auto& thr: tasks)
thr.join();
std::cout << counter << '\n';
}
Output
1000000 // Without data races
Volatile keyword
The volatile keyword in C++ is a type qualifier that is applied to a variable when it is declared. It tells the compiler that the value of the variable may change at any time, without any action being taken by the code the compiler finds nearby. The implications of this are quite serious. The volatile keyword is intended to prevent the compiler from applying any optimizations on the code that assume values of variables cannot change “on their own.” The volatile keyword is typically used in the following situations:
- Memory-mapped peripheral registers
- Global variables modified by an interrupt service routine
- Global variables within a multi-threaded application
The volatile keyword cannot remove the memory assignment, cannot cache the variables in register, and cannot change the value in order of assignment.
It is important to note that the volatile keyword should not be used for inter-thread communication. For inter-thread communication, mechanisms such as
std::atomicfrom the C++ Standard Library should be used instead.
Example Using a “volatile” variable does not prevent a data racevolatile.cpp :
volatile.cpp
// A shared variable is modified by multiple threads
// Using a "volatile" variable does not prevent a data race
#include <thread>
#include <iostream>
#include <vector>
#include <atomic>
volatile int counter = 0;
void task() {
for (int i = 0; i < 100'000; ++i)
++counter;
}
int main() {
std::vector<std::thread> tasks;
for (int i = 0; i < 10; ++i)
tasks.push_back(std::thread(task));
for (auto& thr: tasks)
thr.join();
std::cout << counter << '\n';
}
Output
258413 // data races -> Using a "volatile" variable does not prevent a data race
Atomic Operations
The std::atomic template class provides member functions for atomic types in C++. These member functions are in addition to the operations provided for all atomic types. The following are some of the member functions provided by the std::atomic template class:
-
store(): Sets the value of the atomic object to the given value.
-
load(): Returns the value of the atomic object.
-
operator=(): Stores a value into an atomic object.
-
operator T(): Loads a value from an atomic object.
-
exchange(): Atomically replaces the value of the atomic object with the given value and returns the old value.
-
compare_exchange_weak(): Atomically compares the value of the atomic object with the given value. If they are equal, the value of the atomic object is replaced with the new value. Otherwise, the value of the atomic object is unchanged. Returns true if the value was replaced, false otherwise.
-
compare_exchange_strong(): Same as compare_exchange_weak(), but with a stronger guarantee of success.
atomic_operation.cpp
// Demonstrate member functions of atomic types
#include <iostream>
#include <atomic>
int main()
{
std::atomic<int> x = 0;
std::cout << "After initialization: x = " << x << '\n';
// Atomic assignment to x
x = 2;
// Atomic assignment from x. y can be non-atomic
int y = x;
std::cout << "After assignment: x = " << x << ", y = " << y << '\n';
x.store(3);
std::cout << "After store: x = " << x.load() << '\n';
std::cout << "Exchange returns " << x.exchange(y) << '\n';
std::cout << "After exchange: x = " << x << ", y = " << y << '\n';
}
std::atomic_flag
std::atomic_flag is a type of atomic variable in C++ that is used to implement atomic flags, which are boolean atomic objects . Unlike all specializations of std::atomic, std::atomic_flag is guaranteed to be lock-free.
The std::atomic_flag class provides the following member functions:
- clear(): Sets the value of the atomic flag to false.
- test_and_set(): Atomically sets the value of the atomic flag to true and returns the previous value.
-
operator =() The std::atomic_flag class is typically used to implement spin locks, which are a type of lock that repeatedly checks a flag until it is set to a certain value.
- Must be intialized to false atomic_flag lock = ATOMIC_FLAG_INIT;
Spin lock
A spin lock is a type of lock that repeatedly checks a flag until it is set to a certain value. Spin locks are typically used in situations where the lock is expected to be held for a short period of time, and where the overhead of acquiring and releasing a lock is too high. Spin locks are not recommended for general-purpose use, as they can waste CPU cycles and cause performance issues.
The std::atomic_flag class is typically used to implement spin locks, which are a type of lock that repeatedly checks a flag until it is set to a certain value.
std::atomic_flag to implement a spin lock atomic_flag.cpp
// Use std::atomic_flag to implement a spin lock
// which protects a critical section
#include <atomic>
#include <thread>
#include <iostream>
#include <vector>
#include <chrono>
// The atomic_flag must be initialized as false
std::atomic_flag lock_cout = ATOMIC_FLAG_INIT;
void task(int n)
{
// test_and_set()
// Returns true if another thread set the flag
// Returns false if this thread set the flag
while (lock_cout.test_and_set()) {}
// Start of critical section
// do some work
using namespace std::literals;
std::this_thread::sleep_for(50ms);
std::cout << "I'm a task with argument " << n << '\n';
// End of critical section
// Clear the flag, so another thread can set it
lock_cout.clear();
}
int main()
{
std::vector<std::thread> threads;
for (int i = 1; i <= 10; ++i)
threads.push_back(std::thread(task, i));
for (auto& thr : threads)
thr.join();
}
Example code spin lock with the mutex
using_spin_lock_mutex.cpp
// Use std::mutex to protect a critical section
#include <mutex>
#include <thread>
#include <iostream>
#include <vector>
#include <chrono>
std::mutex mut;
void task(int n) {
std::lock_guard<std::mutex> lg(mut);
// Start of critical section
// do some work
using namespace std::literals;
std::this_thread::sleep_for(50ms);
std::cout << "I'm a task with argument " << n << '\n';
// End of critical section
}
int main() {
std::vector<std::thread> threads;
for (int i = 1; i <= 10; ++i)
threads.push_back(std::thread(task, i));
for (auto& thr : threads)
thr.join();
}
Pros and Cons of spin lock
Spin locks are a type of lock that repeatedly checks a flag until it is set to a certain value. Spin locks are typically used in situations where the lock is expected to be held for a short period of time, and where the overhead of acquiring and releasing a lock is too high. The following are some of the pros and cons of using spin locks: Pros:
- Spin locks are fast and efficient for short critical sections.
- They avoid overhead from operating system process rescheduling or context switching.
- They are useful in situations where the lock is expected to be held for a short period of time.
Cons:
- Spin locks can waste CPU cycles and cause performance issues if held for longer durations.
- They can cause starvation if a thread is continuously spinning and not releasing the lock.
- Implementing spin locks correctly is challenging because programmers must take into account the possibility of simultaneous access to the lock, which could cause race conditions.
- Spin locks are not recommended for general-purpose use, as they can waste CPU cycles and cause performance issues.
Hybrid mutex
A hybrid mutex is a type of lock that combines the benefits of both spin locks and traditional locks. Hybrid mutexes spin for a short period of time in anticipation of a quick lock, but eventually block the thread if the lock is not acquired quickly enough. This approach can reduce the overhead of acquiring and releasing a lock, while also avoiding the performance issues associated with spin locks held for longer durations.
Lock-free Programming
Lock-free programming is a technique that allows concurrent updates of shared data structures without the need to perform costly synchronization between threads. Lock-free algorithms are carefully designed data structures and functions to allow for multiple threads to attempt to make progress independently of one another. This means that you do not try to acquire a lock before performing your critical region. Instead, you independently update a local copy of a portion of the data-structure and then apply it atomically to the shared structure with a CAS (Compare-And-Swap). Lock-free programming has the following advantages:
-
Can be used in places where locks must be avoided, such as interrupt handlers.
-
Avoid the troubles with blocking, such as deadlock and priority inversion.
Improve performance on a multi-core processor. Lock-free programming is a challenge, not just because of the complexity of the task itself, but because of how difficult it can be to penetrate the subject in the first place. Lock-free programming is not just programming without mutexes, which are also referred to as locks. At its essence, lock-free is a property used to describe some code, without saying too much about how that code was actually written. One important consequence of lock-free programming is that if you suspend a single thread, it will never prevent other threads from making progress, as a group, through their own lock-free operations. This hints at the value of lock-free programming when writing interrupt handlers and real-time systems, where certain tasks must complete within a certain time limit, no matter what state the rest of the program is in. Lock-free programming is no panacea, though, since a lock-free algorithm is usually more complex to design, and it has other potential issues, such as contention, which can badly affect performance. Lock-free programming should only be applied once you have measured your program and found it has some performance or scalability problem. After implementing the lock-free algorithm, measure again to check that things improved effectively.
References
- https://en.cppreference.com/w/cpp/atomic/atomic_flag/atomic_flag
- https://en.cppreference.com/w/cpp/atomic/atomic_flag
- https://learn.microsoft.com/en-us/cpp/standard-library/atomic?view=msvc-170
- James Raynard, Learn Multithreading with Modern C++ Udemy.